Announcements
Monday March 30, 2026
Improvements to Data Portal Search
We’ve improved the search bar in the IGSR data portal. Search now does a better job of combining normal word matching with partial matching, so it is more likely to find what you expect whether you search by a full name, a shorter term, or part of an identifier.
For example, searching for the data collection “MAGE RNA-seq” now returns the files that are actually linked to that data collection, instead of a much larger mixed set of unrelated files matched through the substring “RNA”. Similarly, searching for a population such as “Toscani in Italy” now behaves more consistently, giving the same expected result as searching for “Toscani”, so you no longer need to know the exact name to get accurate results. See below.
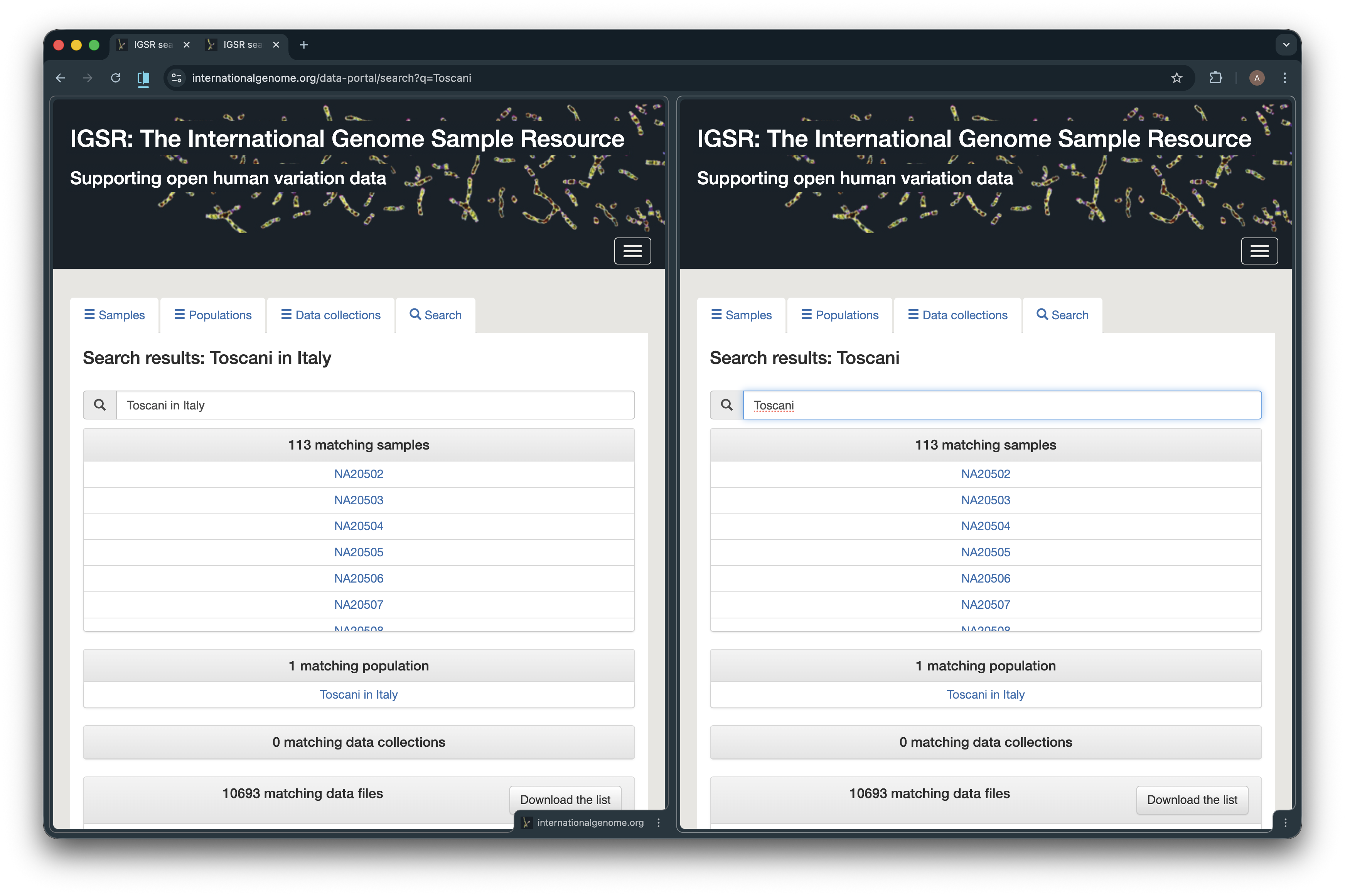
As well as this, we have added a ‘Download the list’ button to allow download of the full file list generated by your search.
Wednesday July 23, 2025
Complex genetic variation in nearly complete human genomes by Logsdon, G.A., et al describes an extensive catalog of variation from the near complete assemblies of 65 human genomes from diverse 1000 Genomes Project samples. These high quality assemblies enable a more comprehensive insight into all variant types, including those within complex regions.
Data is available via the HGSVC3 collection.
Structural variation in 1,019 diverse humans based on long-read sequencing by Schloissnig, S et al describes the characterisation of structural variants in 1019 samples from 26 different the 1000 Genomes Project populations. This study used intermediate-coverage long read sequencing and a novel integration of linear and graph genome-based analyses.
Data is available via the 1KG_ONT_VIENNA collection.
Thursday June 12, 2025
Last year, a group from Johns Hopkins University released Illumina short-read RNA-seq data from 731 cell lines from the 1000 Genomes Project, approximately evenly distributed across the 26 geographically diverse populations. They used these data to examine the genetic sources of variation in gene expression and splicing, including the mapping of expression and splicing quantitative trait loci (e/sQTLs). This work is described in “Sources of gene expression variation in a globally diverse human cohort” by Taylor et al.
More information and links to raw and processed data are available on the MAGE page.
Tuesday September 24, 2024
The Human Genome Structural Variation Consortium (HGSVC) have constructed and analysed complete haplotype sequences, including fully resolved centromeres and segmental duplications, from 65 individuals of diverse ancestries. This forms the first population-scale set of human genome assemblies resolved to near T2T completeness. This work is described in Complex genetic variation in nearly complete human genomes by Logsdon, Ebert, Audano, Loftus et al.
More information and links to data are available on the HGSVC3 page.
Sunday April 21, 2024
New structural variants from the 1000 Genomes Project samples
A new data collection and preprint describing structural variants from 1,019 samples from twenty-six 1000 Genomes Project populations is available.
Long-read sequencing and structural variant characterization in 1,019 samples from the 1000 Genomes Project by Schloissnig,et al uses intermediate-level long read sequencing and a novel method integrating linear and graph based calling methods to type over 160,000 structural variants in this population scale catalogue.
Data is available via: 1KG_ONT_Vienna
Thursday September 30, 2021
We have recently published a Data Note describing our analysis of 505 samples from four Gambian populations in the Gambian Genome Variation Project (GGVP) on GRCh38.
For the analysis we have used a multi-caller site discovery approach along with imputation and phasing to produce a phased biallelic single nucleotide variant (SNV) and insertion/deletion (INDEL) call set. Variation had not previously been explored on the GRCh38 human genome assembly for 387 of the samples. Compared to our previous work with the 1000 Genomes Project data on GRCh38 described here, we identified over nine million novel SNVs and over 870 thousand novel INDELs.
The files generated in this analysis can be accessed from our FTP. Including the alignment files used in the variant identification http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/gambian_genome_variation_project/data/ and the call set itself http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/gambian_genome_variation_project/release/20200217_biallelic_SNV/
More information on the samples analysed in this work can be found in the IGSR portal.
Frequency distributions and genotypes are available in Ensembl.
Friday August 14, 2020
3,202 samples at high-coverage from NYGC
Earlier this year, the New York Genome Center (NYGC) released high-coverage (30x) data for an additional 698 samples from the 1000 Genomes Project sample collections. These 698 samples are related to the original set of 2,504 samples previously sequenced by NYGC. The 2,504 samples are a set of samples unrelated to each other that made up the panel used by the 1000 Genomes Project in its third (and final) phase. This brings the total number of samples sequenced to high-coverage by NYGC to 3,202, in work funded by NHGRI.
NYGC aligned the data to the GRCh38 reference assembly and the CRAMs have been shared and are listed in our data portal. These files can be accessed from FTP sites hosted by EMBL-EBI and NCBI, and are also hosted on AWS and AnVIL. Details on accessing and using the data can be found on our page for this data collection.
This high-coverage data adds to the previous data sets, giving us:
-
The phase three 1000 Genomes Project low-coverage and exome data on GRCh37, as used for the 1000 Genomes Project phase three analysis published in 2015
-
The phase three 1000 Genomes Project low-coverage and exome data realigned to GRCh38 (used to support recalling from the data against GRCh38)
-
30x high-coverage data from NYGC on GRCh38, where an integrated call set is being produced and preliminary call sets have been shared
These data collections, covering large numbers of samples, are supplemented by other data collections in IGSR where a wider range of technologies have been applied to subsets of the samples. Genomic sequence data is also available for samples that were not part of the 1000 Genomes Project. Our data portal can be used to explore the main data sets in IGSR, with additional (and preliminary) data sets available via our FTP site.
Wednesday February 26, 2020
Infrastructure improvements 16-20th March
To enable future expansion of EMBL-EBI’s resources and services, one of the data centres supporting our services will be moving to a new location in the period 16-20th March. The data hosted by IGSR will remain available throughout this time. Data can be accessed via Globus and FTP. The usual FTP URL ftp.1000genomes.ebi.ac.uk may experience some downtime but the data can also be accessed via FTP at ftp.ebi.ac.uk/1000g. Our Aspera download service is expected to experience downtime during this period and we apologise for any inconvenience this may cause. Should you have any questions please contact us at info@1000genomes.org.
Tuesday March 12, 2019
Variant calls from 1000 Genomes Project data on the GRCh38 reference assembly - updates
We have produced an extended integrated and phased biallelic SNV and INDEL call set. This uses the same input data sets as our biallelic SNV call set but now includes INDELs in the creation of the phased call set.
The files include: per chromosome files with genotypes for all samples, a genome wide sites file and genotype files for each of the supporting call sets. The main files contain only unrelated individuals, with details for related individuals available in a separate set of files. Data files are available at: http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/1000_genomes_project/release/20190312_biallelic_SNV_and_INDEL/
A data note describing the biallelic SNV set is now available at Wellcome Open Research.
We will work toward making details of the SNV and INDEL data set available as soon as possible. The data is in the process of being submitted to EVA.
Please contact info@1000genomes.org with any questions.
Monday December 17, 2018
Variant calls from 1000 Genomes Project data calling against GRCh38
An integrated and phased biallelic SNV call set, generated from alignments of the 1000 Genomes phase three low coverage and exome sequence data, is available on our FTP site. These calls were called directly against GRCh38. This data set combines call sets generated using GATK, FreeBayes and BCFtools, with subsequent imputation and phasing carried out using Beagle and SHAPEIT2. A recent poster describing the methods used in generating this data is available and a data note is in preparation. We are also in the process of submitting the data to EVA/dbSNP.
The files include: per chromosome files with genotypes for all samples, a genome wide sites file and genotype files for each of the supporting call sets. The main files contain only unrelated individuals, with details for related individuals available in a separate set of files.
Data files are available at: http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data_collections/1000_genomes_project/release/20181203_biallelic_SNV/
We will work toward releasing a pre-print of the data note as soon as possible but, in the meantime, please contact info@1000genomes.org with any questions.
Wednesday March 14, 2018
Our FTP site will be undergoing maintenance on Thursday 22nd March. This work is due to take place between 10.30am and 2.30pm GMT. During this time, we expect read access to be interrupted, which may disrupt large downloads. The service is expected to return to normal after this period.
If you have any questions regarding this work, please contact us at info@1000genomes.org.
Wednesday July 12, 2017
Our FTP site will be undergoing maintenance on Friday 21st July. For part of the time that this work is in progress, read access will not be available. The maintenance is scheduled to start at 10am BST with an estimated completion time of 10pm BST. We anticipate that read access will be unavailable for three to four hours within this period.
If you have any questions regarding this work, please contact us at info@1000genomes.org.
Friday July 07, 2017
Our Aspera service is being updated. As part of this work, the service is being moved to new hardware and the configuration is being updated.
The service can be used as before but command line users should add the port specification -P33001 to their command. In addition, users whose firewalls block such connections by default will need open ports to the EBI IP address 193.62.193.135. More information on working with Aspera is available in our description of using Aspera to download data.
The upgrade will come into effect from the end of July 2017. The above changes are compatible with the existing service, so we encourage users to adopt any necessary changes now. Prior to the upgraded service coming into use at the end of the month, it is available for testing at fasp-beta.ebi.ac.uk.
Should you have any queries about these changes, please contact us at info@1000genomes.org.
Wednesday May 24, 2017
1000 Genomes GRCh38 alignments published
The alignments of the 1000 Genomes data to GRCh38 the we announced previously are now described in GigaScience.
Details of the alignments are available in the publication and earlier announcement but please contact us at info@1000genomes.org if you have any questions.
Friday May 05, 2017
An updated set of files showing the 1000 Genomes phase three variation calls on GRCh38 is now available. These files are based on dbSNP 149 and a “liftover” mapping from the GRCh37 genome assembly used by the 1000 Genomes Project to the newer GRCh38 assembly. In lifting over, equivalent regions of the two assemblies are identifed, enabling coordinates in one assembly to be mapped to the other. The liftover was done by dbSNP, with additional work contributed by EGA and EVA. As the files contain data from dbSNP, structural variants (those greater than 50bp in length) are not present in these files but can be accessed via Ensembl.
The files are available on our FTP site.
If you have questions about these files, please contact us at info@1000genomes.org.
Friday January 06, 2017
We have now closed the user survey, which we opened in November, and would like to thank everyone who took the time to respond. The information gathered in the survey will assist in the future development of the resources we provide.
While the survey has now closed, we still appreciate feedback. If you have any further comments or suggestions, please contact us at info@1000genomes.org.
Wednesday November 30, 2016
Help improve access to 1000 Genomes data
We are conducting a user survey, to help us improve the accessibility of the 1000 Genomes data. The survey takes around five minutes to complete and we would welcome your participation, which will help guide the development of this resource.
Update: As of 6th January, our survey has closed. However, feedback is welcome at info@1000genomes.org.
Monday November 28, 2016
1000 Genomes and IGSR data resources webinar available
A recording of the webinar “Introduction to 1000 Genomes Project and IGSR data resources”, which took place on 16th November 2016, is now available. You can find further details and view the recording via EBI Train online.
Friday November 18, 2016
The IGSR helpdesk at info@1000genomes.org will be closed temporarily from 5pm GMT on Thursday 24th November until 9am GMT on Monday 28th November. This is to enable migration of the system to new infrastructure. During this time, any messages sent will be held in a queue. You will not receive any confirmation of your email, as this is automatically generated by the system. If we have not responded to you by 5th December, please contact us again. We apologise for any inconvenience this may cause.
Update: as of 28th November, this work has been completed.
Monday October 17, 2016
Due to essential maintenance, the 1000 Genomes helpdesk email will be shut down for approximately 48 hours, beginning at 9 am (BST) on 24th October. Any emails sent during this time will be held in a queue, and we will respond to them when the system is up and running again, although there may be some delay. You will not receive any confirmation of your email, as this is automatically generated by the system.
We will update you when the system is back.
We apologise for any inconvenience this may cause.
Friday September 23, 2016
EBI is hosting a webinar providing an “Introduction to 1000 Genomes Project and IGSR data resources” on 16th November 2016. For further details and to apply for a place, visit EBI training.
Friday August 19, 2016
Data centre scheduled maintenance
Due to scheduled electrical maintenance in one of our data centres, there is the possibility that our services may experience interruptions between 26th and 30th August.
Please email us at info@1000genomes.org if you have any questions.
Thursday June 23, 2016
GRCh38 genome accessibility masks for 1000 Genomes data
As part of the 1000 Genomes Project, which parts of the genome were accessible to the sequencing methods being used was assessed. This was done by looking at the amount of sequence data that aligned to any given location in the reference genome used by the project (GRCh37). Files were created which could be used to mask regions of the genome, if it was considered that they were not accessible to the technologies used.
The sequence data from the 1000 Genomes Project has since then been aligned to the newer reference genome, GRCh38. Based on these alignments, new accessibility masks on GRCh38 have been created and are now available.
Further details on the new mask files are available and information on how the original mask files were used can be found in the main publication from the 1000 Genomes Project.
Tuesday June 07, 2016
Due to necessary maintenance work, there is a possibility that our genome browser may be unavailable for a short period between 10am and 11am British Summer Time on Wednesday 7th June. We are sorry for any inconvenience this may cause. Data from 1000 Genomes will, however, still be accessible via Ensembl.
Monday May 09, 2016
The IGSR Data Portal - Beta Release
We have built a new tool to allow users to explore all the data from the 1000 Genomes Project and other groups hosted through our website and ftp site.
You can access this new tool using the URL /data-portal or the portal link in the page banner.
This is represents a beta release of the portal. We are working to improve it and will add new features over the coming months.
Please email us at info@1000genomes.org to let us know if you like the portal, if anything doesn’t work as expected or if you have any other feedback.
Tuesday April 26, 2016
Modern DNA reveals ancient male population explosions linked to migration and technology
An analysis of the chrY data from the 1000 Genomes Project phase 3 release has revealed punctuated bursts in human male demography. This study identified more than 65,000 variant positions from 1244 men, from 26 different populations. It was published in Nature Genetics this week.
Poznik GD et al. Punctuated bursts in human male demography inferred from 1,244 worldwide Y-chromosome sequences is published in Nature Genetics 25 April 2016 DOI: 10.1038/ng.3559
The chrY variant calls and supporting information can be found in our Phase 3 release directory
Tuesday February 23, 2016
An update to the 1000 Genomes Website
We have released a major update to the 1000 Genomes Website. The 1000 Genomes Project data is now maintained by the International Genome Sample Resource (IGSR). IGSR aims to support and extend the 1000 Genomes Project data. You can read more about IGSR on our about page.
We are in the process of updating all the context to reflect the ongoing efforts with the project data. If you find any issues or can’t find an old page, please email info@1000genomes.org
Wednesday December 16, 2015
GRCh38 alignments for Exome and High Coverage 1000 Genomes Data
We hare realigned exome data from 2692 samples and high coverage PCR-free data from 24 samples, generated for the 1000 Genomes Project to the GRCh38 human assembly.
The alignment is against the full assembly including the GRC maintained alternate loci sequences and decoy and additional HLA sequences from the IMGT.
Our fasta file can be found in the reference directory.
The alignment was carried out using a new alt-aware version of BWA-mem. The alignment files themselves can be found in the data_collections/1000_genomes_project/data directory. The exome alignment index, high coverage alignment index and sequence.index can be found in the data_collections/1000_genomes_project directory.
Please note, these files are now being distributed in CRAM format, rather than BAM format. You can find more details about CRAM in this README. Full details of our alignment pipeline can be found in the alignment pipeline README.
If you have any questions please email info@1000genomes.org.
Friday November 27, 2015
Changes to the 1000 Genomes Globus endpoint
EMBL-EBI has recently rearranged its Globus hosted endpoints.
This means the Globus endpoint for 1000G data is changing from ebi#1000g to ebi#public (‘1000g’ subfolder). The old endpoint will be discontinued shortly. The new endpoint is configured to achieve increased reliability and performance. If you have any questions about the change please contact info@1000genomes.org.
Friday October 16, 2015
GRCh38 mapping of the Illumina Platinum Genomes CEU pedigree
We have aligned the Illumina Platinum pedigree sequence data to GRCh38. The data was aligned to the full assembly including the GRC maintained alternate loci along with decoy and additional HLA sequences from the IMGT. A copy of the FASTA file can be found in our reference directory. The alignment was carried out using a new alt-aware version of BWA-mem.
The alignment files themselves can be found in the data_collections/illumina_platinum_pedigree/data directory.
The alignment index and sequence index can be found in the data_collections/illumina_platinum_pedigree directory.
Please note, alignment files are now being distributed in CRAM format, rather than BAM format. You can find more details about CRAM in this README
Further details of our alignment pipeline can be found in the data collection README.
If you have any questions please email info@1000genomes.org.
Wednesday October 14, 2015
Slides are now available from the #ASHG15 1000 Genomes Tutorial
You can now find the slides presented at the ASHG 2015 1000 Genomes tutorial in Baltimore on the tutorial page.
If you have any questions about the contents of the slides or our data please email info@1000genomes.org
Saturday October 10, 2015
GRCh38 mapping of the 1000 Genomes low coverage data is now available
We have realigned the low coverage 1000 Genomes sequence data to GRCh38. We aligned to the full assembly including the GRC maintained alternate loci sequences and decoy and additional HLA sequences from the IMGT, our fasta file can be found in our reference directory. The alignment was carried out using a new alt-aware version of BWA-mem
The alignment files themselves can be found in the data_collections/1000_genomes_project/data directory.
The alignment index and sequence.index can be found in the data_collections/1000_genomes_projectdirectory.
Please note, these files are now being distributed in CRAM format, rather than BAM format. You can find more details about CRAM in this README
Full details of our alignment pipeline can be found in the alignment pipeline README
If you have any questions please email info@1000genomes.org
Tuesday October 06, 2015
Phase3 Mitochondrial Chromosome Variants now available
Mitochondrial chromosome variants are now available for the Phase 3 individuals from our FTP site
For any more information about the variants or the rest of the dataset please email info@1000genomes.org
Wednesday September 30, 2015
A global reference for human genetic variation
The Phase 3 publication, A global reference for human genetic variation and the Phase 3 Structural variation publication, An integrated map of structural variation in 2,504 human genomes are now available from Nature alongside a celebration of 25 years of the Human Genome Project
The variants from the Phase 3 analysis are available in ftp/release/20130502/ and extended information about the SV dataset can be found in ftp/phase3/integrated_sv_map/.
Both these papers are open access and should be free for everyone to read and download.
If you have any questions about the data these papers are based on or how to access it please email info@1000genomes.org
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/release/20130502/
Tuesday September 15, 2015
The 1000 Genomes Project is holding a tutorial giving and overview of the 1000 Genomes Project, how to access the data and explaining different use cases for the data.
This tutorial will be held in the Baltimore Convention Centre, Room 327, Level 3.
For more details about the program please see the tutorial page
No registration is needed.
Email info@1000genomes.org if you have any questions.
Monday September 07, 2015
Our plan to rearrange the 1000 Genomes FTP site
Starting from the 14th September, we plan to rearrange the 1000 Genomes FTP site to reflect our on going efforts to provide support for the data generated by the 1000 Genomes Project and other data created on the 1000 Genomes cell lines.
This restructure involved creating a data_collections directory which will hold directories for each project or dataset. We plan to remove the headline ftp/data directory and move specific datasets into those data collection directories.
We are also improving our top level FTP READMEs and index files and the old files will be moved into a historical_data directory.
You can get an overview of the planned changes from this attached pdf
We will produce full changelogs which reflect these file moves and no files will be deleted.
If you have any questions about our plans please email info@1000genomes.org
Wednesday May 27, 2015
Phase3 alignment BAM files and sequence read fastq files have been moved
In preparation for publication of the phase3 manuscript, we have moved all phase3 BAM files and fastq files from
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data
to
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/phase3/data
The directory structure does not change under data/
Please note that the phase3 variant call VCF files under ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/release/20130502 stay where they are.
Thursday November 20, 2014
EMBL-EBI 1000 Genomes FTP site will be at reduced capacity between November 21th and December 8th
The EMBL-EBI FTP site will be at reduced capacity between November 21st and December 8th due to EMBL-EBI wconsolidating its web infrastructure into a single data centre.
Please use the NCBI FTP site in preferance where possible during this period.
If you have any questions about this please email info@1000genomes.org
Monday November 17, 2014
Phase 3 Imputation Panels from Beagle, Mach and Impute2
Imputation panels based on the Phase 3 release are now available from Beagle, Mach and Impute2
Thursday November 06, 2014
Phase3 variant calls for chrY are available, variant calls for chrX have been updated
Our final release of the Phase 3 variant set is now available on the FTP site, including a newly added VCF file for chrY.
The chrY variant calls were made with a different process from that of the autosomes; a separate README is available in the release directory describing some details.
The chrX VCF file has been updated to include standard annotation including DP, continental super-population allele frequency.
The site file in the release directory is now wgs containing autosomes, chrX and Y.
Two algorithms were used to discover short tandem repeats (STRs) in the phase3 data. However the STRs did not make into the final integrated call set. They are now available separately here.
The VCF files in the main release directory are also now available here in BCF format for faster processing time.
This release includes super population allele frequencies in the main release VCFs and functional annotation from the Ensembl Variant Effect Predictor along side many other datasets in the supporting directory. The complete list of data is covered in the Supporting Directory README. The issues which have been raised and resolved since our initial release are covered in the Known Issues README.
Please send any questions about this data set to info@1000genomes.org
Saturday October 18, 2014
Short Tandem Repeats added to the 1000 Genomes Release #ASHG14
We have added two sets of STR predictions and genotypes to the 1000 Genomes dataset.
These are available in the supporting directory strs.
The call set were created using LobSTR and RepeatSeq respectively.
The sites are genotyped in all 2535 individuals who were used in our final release. This includes the 31 individuals who are related to other individuals in the main call set.
Saturday October 18, 2014
Chromosome X variants added to the final release #ASHG14
We have now added a set of Chromosome X variants as part of our final release.
The genotypes and sites are available in our main release directory.
We will update the file during November. We need to add functional annotation and super population allele frequency and per site sequence depth information.
Wednesday September 24, 2014
The 1000 Genomes project is holding a tutorial during ASHG 2014.
The 1000 Genomes Project has released the variants, genotypes, and integrated haplotypes for the complete set of 2504 samples from 26 populations. This tutorial describes the data sets, how to access them, and how to use them.
The tutorial will be on Sunday 19th between 8 and 9:30pm in the Convention Centre, Room 24ABC in the Upper Level.
The program is listed on our tutorial web page.
No registration is needed.
Please send any questions about the tutorial to info@1000genomes.org
Monday September 15, 2014
The Phase 3 Variant set with additional allele frequencies, functional annotation and other datasets
Our final release of the Phase 3 variant set is now available on the FTP site.
This update represents version 5 of our release. The issues which have been resolved since our initial release are covered in the Known Issues README
This release includes super population allele frequencies in the main release vcfs and functional annotation from the Ensembl Variant Effect Predictor along side many other datasets in the supporting directory. The complete list of data is covered in the Supporting Directory README
Please send any questions about this data set to info@1000genomes.org
Wednesday June 25, 2014
The Allele Frequency Calculator #1000GB
We have created a new tool to calculate population specific allele frequencies. The Allele Frequency Calculator will calculate and provide a table of population specific allele frequencies from a vcf file and sample panel file.
The tool is documented on this website
The tool currently has two run modes, the first gives you the allele frequencies for a particular population. The second is run by selecting the ALL population and this gives you the allele frequency for all the populations as well as the global allele frequency.
Please do note in genomic regions which are very variant dense or very large regions the tool will run more slowly.
Please send any questions about the tool to info@1000genomes.org
Tuesday June 24, 2014
The Initial Phase 3 variant list and phased genotypes
The initial call set from the 1000 Genomes Project Phase 3 analysis is now available on our ftp site in the directory release/20130502/.
These release contains more than 79 million variant sites and includes not just biallelic snps but also indels, deletions, complex short substitutions and other structural variant classes. It is based on data from 2535 individuals from 26 different populations around the world.
More details about the variant set can be found in the README
Please send any questions about this data set to info@1000genomes.org
Tuesday June 17, 2014
The 1000 Genomes FTP site now available through Globus Online
The 1000 Genomes FTP site is now available as an endpoint in the Globus Online service.
The endpoint name is ebi#1000genomes
Our FAQ has more details about how to access the data via Globus.
Thursday February 20, 2014
1000 Genomes Project and Beyond
1000 Genomes Project and Beyond
24-26 June 2014
Churchill College, Cambridge, UK
This Wellcome Trust conference will focus on advances enabled by the 1000 Genomes Project, including the new directions in genetics and genomics that it has facilitated. It is the latest in the successful series of community meetings for the HapMap and 1000 Genomes Project, marking the end of the 1000 Genomes Project this summer.
Scientific sessions will include:
- Patterns of genetic variation within and between populations
- Management and processing of whole genome sequence data
- Whole genome sequencing in complex and rare diseases
- Human evolution
- Functional analysis of variation
- Genome sequencing: the past, present and future
Scientific programme committee
- Richard Durbin, Wellcome Trust Sanger Institute, UK
- Goncalo Abecasis, University of Michigan, USA
- David Altshuler, Broad Institute of Harvard and MIT, USA
- Lisa Brooks, National Human Genome Research Institute, USA
- Gil McVean, University of Oxford, UK
For further information, visit the Wellcome Trust Scientific Conferences Page
Monday January 06, 2014
Cell lines and DNA samples and panels are available from the Coriell Cell Repository
All the samples from the 1000 genomes are available as lymphoblastoid cell lines (LCLs) and LCL derived DNA from the Coriell Cell Repository as part of the NHGRI Catalog. In addition Standard Population DNA Panels for the 1000 Genomes and HapMap projects are available at $1000 or less each.
A full listing of all the populations available can be see on the Coriell Cell lines and DNA page.
Monday October 21, 2013
New version of the 1000 Genomes ensembl browser #ASHG13
Our 1000 Genomes Browser has been updated to contain Ensembl v73. This contains the majority of the Phase 1 Integrated release.
You can find our tutorial here.
Thursday October 10, 2013
The 1000 Genomes project is giving a tutorial during ASHG 2013 in Boston. This meeting is free for the public to attend.
This meeting is free for the public to attend but we ask that you register so we know how many people to expect.
For full details of the schedule please see our 2013 tutorial page.
Friday October 04, 2013
Integrative Annotation of Variants from 1092 Humans: Application to Cancer Genomics
The Functional Analysis group from the 1000 Genomes Project Consortium have published its findings based on the Phase 1 integrated analysis in Science today.
The functional annotation itself is available from the phase1 analysis results directory on our FTP site.
We also provide the supplementary information associated with the paper in the phase1 paper directory
Please note if you end up here after the 30th September 2015, it is likely due to an error in twitter links. You are probably looking for our Phase 3 publication announcement.
Tuesday September 17, 2013
ShapeIt2 phased haplotypes for the Phase1 integrated variant calls
Olivier Delaneau and Jonathan Marchini have provided improved haplotypes for the phase1 integrated call set on the autosomes generated using SHAPEIT2.
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/phase1/analysis_results/shapeit2_phased_haplotypes/
Using a set of validation genotypes at SNP and biallelic indels Olivier and Jonathan have been able to show that these haplotypes have lower genotype discordance and improved imputation performance into downstream GWAS samples, especially at low frequency.
Thursday August 01, 2013
Phase3 lossy CRAMs available now
Lossy CRAMs for mapped phase3 BAMs are available now on the ftp site:
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data
In these lossy crams, the quality scores were binned according to Illumina 8-binning scheme; tags OQ, BQ, CQ were dropped.
Two index files for the lossy CRAMs can be found in
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices with the following names:
20130502.alignment.lossy_cram.index
20130502.exome.alignment.lossy_cram.index
The average size of the lossy crams is 30.7% and 31.0% of that of the low coverage and exome BAMs, respectively.
The above information can also be found in ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/README.crams
Friday July 26, 2013
Complete Genomics Data Release
The CG data for 427 samples are available now at:
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data
Of the 427 samples, 6 samples of the PUR trio and KHV trio were sequenced in both blood and LCL thus the total count of datasets is 433.
CG BAMs, VCFs and tar files can be found under subdirectory NAxxxxxx/cg_data; these files are listed in an index file:
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/complete_genomics_indices/20130820.cg_data.index
| The reference data came along with the CG data can be found under subdirectory NAxxxxxx/cg_data/REF_[LCL | Blood | Buffy]; an index file is put together to summarise the reference files: |
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/complete_genomics_indices/20130815.cg_ref_data.index
| We also un-tar the tar ball and put the files under NAxxxxxx/cg_data/ASM_[lcl | blood | buffy]; the untarred files are listed in the following index file: |
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/complete_genomics_indices/20130725.cg_data.untar.index
Saturday May 25, 2013
Official release of phase3 alignment data is available
The official release of phase3 low coverage and exome data is completed and available on the ftp site. The alignment data were generated by Sanger Center. All BAMs have gone through the DCC QA process; samples and runs identified as problematic have been withdrawn. The 20130502.analysis.sequence.index has been updated to reflect the withdrawn:
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130502.analysis.sequence.index
or
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/analysis.sequence.index
Here are the main alignment index files:
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/20130502.low_coverage.alignment.index
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/20130502.exome.alignment.index
or
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment.index
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/exome.alignment.index
There are 2535 samples in the index files; all of them passed QA and have both exome and low coverage data.
In the alignment_indices directory ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/, you may find associated stats files and summary bas files and an exome HsMetrics file:
20130502_20120522.alignment_stats.low_coverage.csv
20130502_20120522.alignment_stats.exome.csv
20130502.low_coverage.alignment.index.bas.gz
20130502.exome.alignment.index.bas.gz
20130502.exome.alignment.index.HsMetrics.gz
20130502.exome.alignment.index.HsMetrics.gz.stats
A handful samples passed all QA but only have either low coverage data (23) or exome data (16); we keep the BAM files for these samples at
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/phase3_EX_or_LC_only_alignment
Two alignment index files can be found in the same directory:
20130502.exome_only.alignment.index
20130502.lc_only.alignment.index
Monday April 22, 2013
Final sequence index released!
The final sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130502.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130502.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices. We have achieved our goal of 2500 samples for both low coverage and exome projects! The overlap between >5Gb exome samples and >10Gb low coverage samples is also greater than 2500.
Monday April 15, 2013
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130415.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130415.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices. We have achieved our goal of 2500 samples for both low coverage and exome projects! The overlap between >5Gb exome samples and >10Gb low coverage samples is 2466.
Monday April 08, 2013
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130408.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130408.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices. We are very close to our goal of 2500 samples for both low coverage and exome projects!
Tuesday April 02, 2013
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130402.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130402.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices.
Monday March 25, 2013
New Sequence Index is released
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130325.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130325.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices. Here is a snapshot for your convenience. Please note that we are now reporting number of samples with greater than 10Gb for low coverage data and greater than 5Gb for exome data by population.
Tuesday March 19, 2013
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130319.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130319.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices. Here is a snapshot for your convenience. Please note that we are now reporting number of samples with greater than 10Gb and 5Gb of data by population.
Monday March 11, 2013
Another sequence index file is released on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130311.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130311.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices.
Wednesday March 06, 2013
A new sequence index is now available on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130305.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130305.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices.
Wednesday February 20, 2013
In order to meet phase3 release timelines, we are going to make more frequent sequence index releases. Basically we are checking data submission weekly; a new sequence index will be released when 25 or more new samples or 250GB or more new sequences are detected. This way BAM files can be created incrementally without much delay.
A new sequence index is now available on the FTP site
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130218.sequence.index
The corresponding analysis.sequence.index that contains only >70bp long Illumina reads is
http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20130218.analysis.sequence.index
You may find different stats files for this release in http://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices
Wednesday December 19, 2012
Complete Genomics Data Available
Complete Genomics data for 57 samples are available now in
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/data
The data are organised in above directory under sample_name/cg_data. Each sample has a CG native ASM tar file, an evidence BAM file, an evidence BAM file with supporting reads, a VCF file, and corresponding index files (bai and tbi).
An index for these files is
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/complete_genomics_indices/20121201.cg_data.index
Thursday December 13, 2012
Update to the 1000 Genomes Browser
Our 1000 Genomes Browser has been updated to contain Ensembl v69. This contains the majority of the Phase 1 Integrated release.
You can find our tutorial here.
Tuesday December 11, 2012
New Sequence Data is Available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at:
Going forward the project plans to produce alignments and variant calls using only Illumina platform sequence data with 70bp reads or longer. This data set has been put into the analysis.sequence.index. There is more info about this in our FAQ
Instructions for data download and Aspera
Sequence index and Statistics files
Tuesday December 11, 2012
A new alignment release is available on the ftp site. The exome and low coverage alignment.index files describes the location of all the alignment files This has been made based on the 20120522.analysis.sequence.index. All BAMs have gone through the DCC QA process; samples and runs identified as problematic have been withdrawn.
Friday November 09, 2012
1000 Genomes Tutorial and Poster Slides #ASHG2012
The slides from our tutorial session which was held on Wednesday 7th and the Data Access Poster are both available from our website
Wednesday October 31, 2012
An integrated map of genetic variation from 1092 human genomes
The Phase 1 publication, An Integrated map of genetic variation from 1092 human genomes is now available from Nature and can be downloaded directly from the ftp site. The paper is distributed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported licence. Please share our paper appropriately.
All the data files associated with this paper can be found in our phase1 analysis results directory.
Please note if you are looking for our Phase 3 paper, you might be here from twitter in error, our Phase 3 announcement is a global reference for human variation
Tuesday October 23, 2012
#ASHG2012 1000 Genomes Tutorial, Wednesday 7th November 7-9:30pm San Francisco Marriott Marquis
The 1000 Genomes Project is holding a tutorial during ASHG 2012 on Wednesday 7th November 7:00 to 9:30pm at the San Francisco Marriot Marquis.
The 1000 Genomes Project has released the sequence data and an integrated set of variants, genotypes, and haplotypes for the 1092 samples in the phase 1 set, and the sequence data for the phase 2 set. This tutorial describes the data sets, how to access them, and how to use them.
There are more details on the tutorial page. Please use this form to sign up.
Thursday September 06, 2012
Genome Accessibility information now available on the 1000 Genomes Browser
Two Accessibility Tracks have now been added to the 1000 Genomes Browser
This information was built using sequence data from the phase1 dataset
The two tracks are called the 1000 Genomes Pilot Accessibility Mask and the 1000 Genomes Strict Accessibility Mask.
There is a README which describes how this data set was created. The raw bed and fasta files are also available in the accessible genome ftp directory
Monday July 02, 2012
Phase 1 analysis results including chrY and chrMT variant calls
Analysis results based on our phase1 integrated variant call set are now available.
This includes chrY and chrMT variant calls, functional annotation of our variant calls and local area ancestry inference for our admixed populations.
Full details of the directory contents can be found on this webpage.
Tuesday May 22, 2012
New Sequence Data is Available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at:
Instructions for data download and Aspera
Sequence index and Statistics files
Wednesday May 09, 2012
Update to 1000 Genomes Browser #bog12
Our 1000 Genomes Browser has been updated to contain the Integrated Phase 1 variant set. It has also be moved to Ensembl version 65.
This update includes improved navigation and a track for the Exome Sequencing Project SNPs
You can find our tutorial here.
Sunday April 29, 2012
Data management and Community access paper published
Nature Methods has published The 1000 Genomes Project:data management and community access.
This paper describes how the consortium manages its data and the tools we have created to make access easier.
The paper itself is freely available under a creative commons license
Article PDF Supplementary Info PDF
Friday April 20, 2012
A new sequence index is available now
The new index can be found at ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/sequence_indices/20120419.sequence.index
Associated stats can be found in the same directory.
Thursday April 05, 2012
The 1000 Genomes Project Community Meeting 12th and 13th July 2012
The 1000 Genomes Project is holding a Community Meeting at the University of Michigan, Ann Arbor on the 12th and 13th of July 2012
The Meeting is meant to showcase advances made by the 1000 Genomes Project, both with respect to methods for generation and analysis of sequence data and in our understanding of human genetic variation, show how 1000 Genomes Project data and methodology is advancing our understanding of human disease, both in disease studies that use 1000 Genomes Project data as a reference and in studies that are applying population sequencing and other project technologies in phenotyped samples, highlight other cutting edge sequencing studies and technologies in humans and finally to generate discussion and lay the ground work for the next round of community resource sequencing projects.
For more details and to register please go to http://1000gconference.sph.umich.edu/
Thursday March 29, 2012
1000 Genomes Data in the Amazon Web Service Cloud
The 1000 Genomes data set is now available in the Amazon Web Service Cloud(AWS)
For more information about how to access and use the data in the cloud please look at our documentation
More details are available in the NIH Press Release
Friday March 16, 2012
Updated Integrated Phase 1 Release Calls
This March 2012 release represents a improved set of our integrated phase 1 variant release. This release represents version 3 of an integrated variant call set based on both low coverage and exome whole genome sequence data. This is an updated set from the version 2 (February 2012) of the 20110521 release. For this release approximately 2.38M indels have been filtered from the version 2 call set. See README_v3 for more information.
Our FAQ contains instructions on how to get smaller subsections of these files
Tuesday March 13, 2012
Phase2 alignment data release complete
The official release of phase2 alignment data is complete and available on the ftp site. All BAMs have gone through the DCC QA process; samples and runs identified as problematic have been withdrawn. The 20111114.sequence.index has been updated to reflect the withdrawn.
The alignment index files are:
Low Coverage data (Illumina, 454 and SOLiD)
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/20111114.alignment.index or
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment.index
EXOME data (Illumina and SOLiD)
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/20111114.exome.alignment.index or
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/exome.alignment.index
In the alignment_indices directory ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/alignment_indices/, you may find associated stats files and summary bas files:
Low Coverage:
20111114_20101123.alignment_stats.low_coverage.csv
20111114.alignment.index.bas.gz
EXOME:
20111114_20101123.alignment_stats.exome.csv
20111114.exome.alignment.index.bas.gz
20111114.exome.alignment.index.HsMetrics.gz
20111114.exome.alignment.index.HsMetrics.stats
Thursday March 01, 2012
Using 1000 Genomes Data, A tutorial
We have created a tutorial to give users a basic background into the 1000genomes project.
This includes a series of slides covering the background and history of the project, the structure and format of the raw data, our browser and our tools.
There are exercises for both our browser and web based tools and command line tools which are useful when working with 1000 genomes data.
All the tutorial documents can be found on our ftp site.
Tuesday February 14, 2012
February 2012 Updated Genotypes for Integrated Phase 1 Release
This February 2012 release represents a new improved set of phased genotypes for our integrated phase 1 variant release. This release contains SNPS, short INDELs and Deletions based on low coverage and exome sequencing data across 1092 individuals.
Please note the sites list has been filtered to remove a small number of indels which were discovered to have a high false positve rate. There is more information about this in the README
Our FAQ contains instructions on how to get smaller subsections of these files
Link to additional information:README file
Monday January 30, 2012
New Sequence Data is Available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at:
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Friday January 27, 2012
EBI 1000 Genomes FTP site now also available over HTTP
The EBI 1000 Genomes ftp site is now also available via http
Wednesday January 11, 2012
Trio high coverage BAMs and pilot3 BAMs have been moved
Trio high coverage BAMs generated for pilot2 project have been moved to
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/pilot2_high_cov_GRCh37_bams
Exon targetted BAMs generated for pilot3 project has been moved to
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/technical/pilot3_exon_targetted_GRCh37_bams
Both sets of BAMs are mapped to GRCh37.
Thursday January 05, 2012
The Phase1 BAMs have been moved
In preparation for the incoming of phase 2 BAMs, all phase 1 BAMs have been moved to a phase1 freeze directory -
ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/phase1/ or
ftp://ftp-trace.ncbi.nih.gov/1000genomes/ftp/phase1
Monday December 05, 2011
ChrX variant calls added to October Integrated Variant Set Release
The October 2011 Integrated Phase 1 Variant Release has been updated. It now includes variant calls on chrX.
For more information please see the new README
Tuesday November 15, 2011
New Sequence Data is Available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at:
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Friday November 11, 2011
Update to October 2011 Integrated Variant Set release
The October 2011 Integrated Phase 1 Variant Release has been updated to include additional information like rs numbers from dbSNP, Ancesteral Alleles and Allele Frequencies.
For more information please see the new README
Wednesday October 26, 2011
At ICHG2011 we presented a tutorial about 1000 Genomes Data. The slides from this tutorial can be found here
Thursday October 13, 2011
A new Project browser based on our Interim 20101123 phase 1 variant calls has been released.
It is based on Ensembl release 63.
Please read our tutorial document for more information about the browser.
Wednesday October 12, 2011
October 2011 Integrated Variant Set release #ICHG2011
This October 2011 release represents an integrated set of variant calls and phased genotypes including SNPS, short INDELs and Deletions based on low coverage and exome sequencing data across 1092 individuals.
Our FAQ contains instructions on how to get smaller subsections of these files
Link to additional information:README file
Wednesday October 12, 2011
#ICHG2011 1000 Genomes Project Resources Poster
The Poster which was presented at the ICHG 2011 Poster session on 12th October is available in powerpoint format here
The 1000 Genomes Project Resources
Tuesday September 20, 2011
New Sequence Data is Available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at:
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Thursday September 01, 2011
The project browser based on the 20100804 variant release and has been moved to the latest version of Ensembl, 63.
The new browser features a new Variation Pattern Finder and improvements to the Data Slicer to allow vcf slices to be subselected on the basis of individual or if associations provided by population. All location based pages also now have a get vcf button which transfers you to the Data slicer with the coordinates fill out and the path of the vcf for our 20100804 release filled in. For more information about the new features which are part of the Ensembl project please look at their blog post on the matter
Friday August 12, 2011
Update of the Phase 1 Exome Alignments
The alignments based on the 20110521.sequence.index have been updated.
Illumina data was aligned at Boston College and SOLiD data at Baylor College of Medicine. Full project data is aligned to the GRCh37 human assembly. In the updated release, all Baylor SOLiD BAMs and associated bai and bas files have been replaced; the new BAMs are now re-calibrated and locally re-aligned.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Tuesday July 19, 2011
Release of phase 1 exome alignments
The alignments based on the 20110521.sequence.index have been released. This is the first set of exome alignments to be released by the project.
Illumina data was aligned at Boston College and SOLiD data at Baylor College of Medicine. Full project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Tuesday July 19, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110719.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Tuesday July 12, 2011
New Reference sequence for Phase 2 mapping
A new reference assembly which is to be used in the mapping of the Phase 2 data is now available on our FTP site
All existing phase 1 data will be remapped to this assembly for the phase 2 analysis.
Link to additional information: README
Thursday June 23, 2011
Genotypes for 1094 individuals for the May 2011 snp calls from the 20101123 sequence and alignment release of the 1000 genomes project has now been made. This release is based on the GRCh37 assembly of the human genome and is released in the format VCF 4.0
Our FAQ contains instructions on how to get smaller subsections of these files
Link to additional information:README file
Thursday June 16, 2011
Public Mysql Instance for Browser databases
We have released a public mysql instance of the Ensembl databases which sit behind our browser.
There are more details about this instance on the Public Mysql Instance page.
Please email info@1000genomes.org if you have any questions
Wednesday June 01, 2011
Pilot Study Structural variants available from DGVa
The Database of Genomic Variants Archive (DGVa) have recently released the Stuctural Variants associated with our pilot study paper.
The variants are available from the ftp sites of both the DGVa and dbVar and can be browsed on the dbVar summary page
Saturday May 21, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110521.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Saturday May 21, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110521.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Thursday May 12, 2011
Full Project low coverage SNP call release
SNP calls based on 1094 individuals from the 20101123 sequence and alignment release of the 1000 genomes project has now been made. This release is based on the GRCh37 assembly of the human genome and are released in the format VCF 4.0
Link to additional information:README file
Friday May 06, 2011
The project browser has been updated to include 20100804 variant release and has been moved to the latest version of Ensembl, 62.
A tutorial for the updated browser is available here.
New features include a Data Slicer tool which provides the ability to get subsections of vcf and bam files. Transcript consequences also now include Sift and Polyphen scores for non synonymous SNPs.
The pilot browser is still available at http://pilotbrowser.1000genomes.org
Friday May 06, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110506.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Monday April 11, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110411.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Monday February 28, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110228.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information:Sequence index file format
Wednesday February 16, 2011
Release of Full Project Phase 1 Alignments
The alignments based on the 20101123.sequence.index have been released. There are both new BAM files and updated BAM files with more data were added. For the case of updated files, the older, redundant files have been withdrawn.
Illumina data was aligned at the Sanger Institute and SOLiD data at TGEN. Full project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Wednesday February 16, 2011
Full Project Indel Release
Indels calls from Dindel. These calls are based on 629 individuals from the 20100804 sequence and alignment release of the 1000 genomes project. This release is based on the GRCh37 assembly of the human genome and are released in the format VCF 4.0
Link to additional information:README file
Thursday February 03, 2011
Mapping copy number variation by population scale genome sequencing
| The Structural Variant group from the 1000 Genomes Project Consortium has published its findings based on the pilot data analysis in Nature today. Mapping copy number variation by population scale genome sequencing. The data supporting this paper can be found on the ftp site EBI | NCBI |
Tuesday January 25, 2011
New Sequence Data is available
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20110124.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Sequence index and Statistics files
Thursday December 16, 2010
Full Project Genotype Release
Genotypes and haplotypes have been added to the SNP calls released in November. These calls are based on 629 individuals from the 20100804 sequence and alignment release of the 1000 genomes project. This release is based on the GRCh37 assembly of the human genome and are released in the format VCF 4.0
Link to additional information: README file
Monday November 22, 2010
1000 Genomes Tutorial and Slides Avaliable
The 1000 Genomes Project Data Tutorial was held on Wednesday, November 3, during the American Society of Human Genetics meeting in Washington, DC. The slides and video of the tutorial are publicly available on the NHGRI website.
Tuesday November 09, 2010
Full Project SNP call release
SNP calls based on 628 individuals from the 20100804 sequence and alignment release of the 1000 genomes project has now been made. This release is based on the GRCh37 assembly of the human genome and are released in the format VCF 4.0
Link to additional information:README file
Wednesday October 27, 2010
1000 Genomes Pilot Paper Published
The 1000 Genomes Project Consortium has published the results of the pilot project analysis in the journal Nature in an article appearing on line today. The paper A map of human genome variation from population-scale sequencing is available from the Nature web site and is distributed under the terms of the Creative Commons Attribution-Non-Commercial-Share Alike licence to ensure wide distribution. The paper is also available directly from this link and supporting data for the paper is avilable from our mirror web sites at the EBI and NCBI
Monday October 04, 2010
Release of full project alignment files
The alignments based on the 20100804.sequence.index have been released. There are both new BAM files and updated BAM files with more data were added. For the case of updated files, the older, redundant files have been withdrawn.
Illumina data was aligned at the Sanger Institute and SOLiD data at TGEN. More information is available in the README file linked below. Full project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Monday October 04, 2010
New sequence data is available
The latest release of sequence data from the 1000 Genomes full project is now available. The new sequence.index file can be found at: 20101004.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information: List of new index and statistics files / Sequence index file format
Wednesday August 04, 2010
New sequence data is available
The latest release of sequence data from the 1000 Genomes full project is now available. The new sequence.index file can be found at: 20100804.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information: List of new index and statistics files / Sequence index file format
Tuesday July 20, 2010
Pilot Project Variant call release
Variant Calls from the three pilot projects are now available in VCF 4.0 format. This release includes SNPs, short indels and large scale structural variants. All 1000 genomes pilot project files reference the NCBI build 36 assembly of the human genome
Link to additional information: README file
Monday July 19, 2010
Release of full project alignment files
The alignments based on the 20100611.sequence.index have been released. There are both new BAM files and updated BAM files with more data were added. For the case of updated files, the older, redundant files have been withdrawn.
Illumina data was aligned at the Sanger Institute and SOLiD data at TGEN. More information is available in the README file linked below. Full project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information: New Files / Withdrawn bams
Monday July 12, 2010
Additional sequence data from the 1000 Genomes full project are now available. The current sequence.index file can be found at: 20100710.sequence.index
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information: List of new index and statistics files / Sequence index file format
Sunday June 06, 2010
Release of main project alignment files
The alignments based on the 20100517.sequence.index have been released. BAM files with more data replace older (and now withdrawn) BAM files with less data. Illumina data was aligned at the Sanger Institute and SOLiD data at TGEN. More information is available in from the links below. Main project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Links to additional information: New Illumina Files / New SOLiD Files / List of withdrawn bams
Thursday April 29, 2010
Additional main project sequence files
New main project sequence files are available on the FTP site.
Link to additional information: 20100429.sequence.index / README.sequence_data / README.populations
Friday April 16, 2010
The Pilot 1 mask files have been patched to support creation of *.fai files with SAMtools.
Link to additional information: Changelog
Thursday April 15, 2010
Release of main project alignment files
The first set of alignment files from the main phase of the 1000 Genomes project are now available for download.
Illumina data was aligned at the Sanger Institute and SOLiD data at TGEN. More information is available in the README file linked below. Main project data is aligned to the GRCh37 human assembly.
Data access links: EBI / NCBI / Instructions for data download and Aspera
Link to additional information: Changelog (Illumina files) / Changelog (SOLiD files) / README.alignment_data
Wednesday March 31, 2010
Final release of pilot project SNP calls
The final set of SNPs from Pilots 1, 2 and 3 are now available in VCF format. All 1000 Genomes pilot project files reference the NCBI build 36 assembly of the human genome.
Link to additional information: README file
Tuesday February 23, 2010
Release of main project sequence data
An updated set of sequence data now available on the ftp site. We have also updated the readme to reflect a new column being added to the sequence.index file and the additional statistics file which is now associated with the index.
The population column of the sequence index has also been rationalised to use only the three letter population codes. Definitions of each code can be found in the readme file below.
Links to additional information: sequence.index / README.sequence_data / README.populations
Monday December 21, 2009
Pilot 2 and Pilot 3 SNP calls updated
Updated PIlot2 and Pilot3 SNP calls in VCF format are now available.
Link to additional information: Supplemental and supporting data
Thursday December 17, 2009
1000 Genomes web site back on line
The 1000 Genomes web site at 1000genomes.org is now available again.
As part of the recovery of the site, we had to change all of the passwords for those of you that have wiki accounts. You can request your password by selecting the “Send me my password” link on the left side of the page. You will then receive an automated email with a new password and instructions for activating that password. You may have to check your junk mail box to find this email.
Thursday December 10, 2009
1000 Genomes web site temporarily unavailable
The 1000genomes.org web site is currently unavailable. We are aware of the problem and working to get it corrected.
Tuesday November 24, 2009
A Pilot 1 bam file (plus .bas file): NA18940.SLX.maq.SRP000031.2009_09.unmapped.bam has been added to the ftp site. The new version contains corrected library information.
Links to additional information: Changelog / alignment.index
Wednesday November 18, 2009
Several updates the project alignment files are detailed below:
1. Five pilot 2 chromY bam (plus associated .bai and .bas files) have been withdrawn. This data included female samples mapped to the Y chromosome. Changelog
2. New .bas files for unmapped.bam files on already on ftp site have been added. Changelog
3. Replacement of 166 .bas files. The replacement files contain corrected “library” entries that are consistent with pilot_data.sequence.index file. Changelog
The “alignment.index” file has been updated to reflect these changes: alignment.index
Wednesday November 11, 2009
Updates to filtered fastq files
Updated filtered fastq files have been added to the FTP site. This is a regular monthly update of the filtered fastq files for all the pilots and on-going production project. The update includes replacement of 206 buggy filtered fastq files, as well as addition of 430 new filtered fastq files obtained and screened from ERA.
In addition, 159 replacement filtered fastq files for specific CHB runs have been added to the FTP site.
Links to additional information: Changelog (new files) / Changelog (replacement of 206 files) / Changelog (replacement of 159 CHB files)
Tuesday November 10, 2009
New annotation files for pilot data
New annotation files to be used in the analysis of the pilot projet have been added to the FTP site. These files include
- Phastcons regions of conservation, conserved_noncoding_phastcons_17way.txt.gz This is a set of phastcon non coding conserved regions
- Uniqueness of the genome, hs36_uniqueness_mask.fa.gz, This is a fasta like file with a rating for how unique each postion of the genome is. The associated readme explains the meaning of each score
- Genetic map and Recombination hotspots, genetic_map_b36.tar.gz, Genetic map for the 22 autosomes and a recombination hotspot file
A full list of the annotation can be found on the annotation wiki page.
Link to further information: Changelog.
Monday November 09, 2009
Replacement bams for pilot1 CHB alignments and pilot2 NA19239 to account for the previously missed libraries.
Links to additional information: Changelog / alignment.index
Friday November 06, 2009
Coordination of sequence files
Several fastq files used to create the alignemnt files, but missing from the FTP site have been reinstated to the FTP site.
Links to additional information: Changelog / pilot_data.sequence.index.
Wednesday November 04, 2009
5 replacement pilot 1 .bas files have been added the files replaced were incorrectly labelled SRP000032 in column 3.
Links to additional information: Changelog
Tuesday November 03, 2009
New files containing scripts and data related to the GENCODE annotation for determining conserved noncoding regions and introns have been added to the FTP site.
Data access links: EBI / NCBI.
Links for additional information: Changelog / README / Code download (.tgz).
Monday November 02, 2009
Update of alignment index file
The alignment.index file was not correctly updated after the addition of replacement bams on October 29. This has been corrected.
Links to additional information: alignment.index
Thursday October 29, 2009
48 replacement pilot 2 454 bams (and associated bas and bai) files for NA12878 and NA19240 have been added to the ftp site.
Links to additional information: Changelog (withdawn files) / Changelog (replacement files) / alignment.index
Tuesday October 27, 2009
Replacement BAM files for the CHB population have been added to the DCC ftp site with an up-to-date alignment index file. 42 old BAM files and associated bai and bas files have been withdrawn and replaced by 18 BAM files and associated bai and bas files.
Links to data: EBI
Links to additional information: Changelog (replacement files) / Changelog (withdrawn files)
Friday October 23, 2009
Pilot 1 replacement bam, bai, bas files have been added to the FTP site.
Links to additional information: Changelog (withdrawn files) / Changelog (replacement files)
Wednesday October 21, 2009
Release of new Pilot 3 454 BAM files
A total of 351 new Pilot 3 454 BAM files have been added to the FTP site replacing a set of older BAM files. These files use a more stringent method of duplicate removal. In the changelog files below, those labelled with the pattern 454.ssaha2.SRP000033.2009_09.ba were withdrawn.
Links to additional information: Changelog (replacement files) / Changelog (withdown files)
Monday October 12, 2009
Replacement bam (and .bai, .bas) files added, correcting for withdrawn lanes included in bam file.
Links to additional information: Changelog (replacement files) / Changelog (withdrawn files) / alignment.index
Monday October 12, 2009
Release of 1000 Genomes main project reference genome
The reference genome to be used for the main project is GRCh37 and the files to be used for alignment in the main project are now available. The procedure for creating the reference genome is:
1. Download individual chrs for the GRCh37 assembly from Ensembl: FTP site
2. Download the newer version of the MT (NC_012920): Data link
3. Create a reference with chrs1-22, X, Y, NC_012920 MT, and include the non-chromosomal supercontigs.
The pilot project reference genome (based on NCBI build 36) remains available in the retired_reference directory on the FTP site.
Link to additional information: Changelog (file locations)
Monday October 12, 2009
Pilot 3 consensus target regions and gene list
A pilot 3 gene list and a bed file for pilot 3 consensus exonic target regions as described by Fuli below have been put on the 1000 Genomes ftp site.
Links to additional information: Changelog
Wednesday October 07, 2009
Updated sequence files and new CHB/YRI data
A total of 844 files are added to ftp/data/ directory representing new and replacement filtered fastq files. Replacement files were required for a small number of fastq files with incorrect quality scores. The files with the incorrect quality scores were removed. In the sequence index file the removed files are marked “WITHDRAWN FROM ARCHIVE”.
Links to additional information: Changelog (new files) / Changelog (replaced files) / Changelog (withdrawn files)
Tuesday October 06, 2009
A truncated bam file and the associated bai and bas files have been replaced.
Links to replacement file: EBI / NCBI
Link to additional information: Changelog
Friday October 02, 2009
BAM Statistics files added to FTP site
719 new .bas (bam statistics) files have been added to the FTP site and 1129 .bas files have been replaced. The relpaced files have corrected bam file names and statistics including #_total_bases and %_of_mismatched_bases. The alignment index files will be updated shortly to give #_total_bases and #_mapped_bases for each bam file entry.
Links to additional information: Changelog (new .bas files) / Changelog (replacement .bas files)
Friday October 02, 2009
Availability of QC Passed Fastq files
A set of 33315 fastq files containing sequence reads that have passed a DCC fastq QC process are now available on the FTP site.
The filtered_fastq files contain reads passing the DCC fastq QC process and have been put on the ftp site. The input to the DCC QC pipeline are all fastq files retrieved from ERA, including reads generated by all three pilots and the main project, as of 4 September 2009.
Summary statistics of the current set of files:
Total read count: 143,297,692,374
Total base count: 6,248,070,765,643
Total filtered read count: 130,945,326,161
Total filtered base count: 5,715,866,786,951
Percentage of good reads: 91.38%
Percentage of good bases: 91.48%
Link to additional information: Changelog (list of new files) / QC criteria in README.sequence_data
Friday May 15, 2009
Indel calls have been made by several groups on the trio children NA12878 (CEU) and NA19240 (YRI).
There is a README which describes the call set
These calls are available on the ftp site EBI:NCBI
Sunday February 15, 2009
Initial release of low coverage pilot data
The first set of SNPs and other supporting data from the low coverage individuals is now officially released on the EBI and NCBI FTP sites associated with the 1000 Genomes project.
This intermediate release of results from the 1000 Genomes project consists of the following (all file paths below are relative to the following root on the two mirror ftp sites: ftp://ftp.1000genomes.ebi.ac.uk/vol1/ftp/release/2009_02/ or ftp://ftp-trace.ncbi.nih.gov/1000genomes/ftp/release/2009_02/).
1. SNP calls from 104 individuals in the low coverage pilot, Pilot 1.
See this file: Pilot1/README_SRP000031_2009_02 for more details on how the calls were made and what the file formats are. All the files related to this set of calls, excepting the human genome reference used (see point 3 below), are in the Pilot1 directory.
See this file: Pilot1/alignments.index for a tab-delimited list of alignment files, one per individual, including md5 checksums for each file. The third and fourth columns give the project id for Pilot1, SRP000031, and the identifier for the corresponding individual. The alignment files are in SAM format (see http://samtools.sourceforge.net/).
Please note these are intermediate results, NOT based on the sequencing data from the complete Pilot.
2. The human genome reference files used can be found in the following directory: ../../technical/reference.
The male and female reference files are in gzipped fasta format, and there are also two index files, for indexing directly into the compressed references, for BAM file manipulation. This index format is defined in the README within that directory.
Tuesday December 23, 2008
The first set of SNP calls representing the preliminary analysis of four genome sequences are now available to download through the EBI FTP site and the NCBI FTP site. The README file dealing with the FTP structure will help you find the data you are looking for.
The data can also be viewed directly through the 1000 Genomes browser at http://browser.1000genomes.org. Launch the browser and view a sample region here.
For more information about using the 1000 Genomes browser, download the Quick start guide.
The 1000 Genomes Project announces the release of the first set of SNP calls for 4 individuals that are part of the high coverage pilot project. These SNPs represent the preliminary analysis of a portion of the data so far collected and are released in accordance with the Ft. Lauderdale agreement for community resource projects.
This preliminary release is designed to both provide data to the community and to test the systems used to make the data available including the 1000 Genomes browser available at http://browser.1000genomes.org. Additional updates of this site and the 1000 Genomes browser will take place througout January.
In addition to the SNP files and the 1000 Genomes project browser, raw project data is made available as soon as possible through by NCBI and the EBI. The data consist of README files, fastq files (nucleotides and qualities) suitable for use with most aligners, and md5 checksum data.
Users from the Americas should download the mirrored 1000 Genomes data from NCBI via ftp at: ftp://ftp-trace.ncbi.nih.gov/1000genomes/ or via the Aspera high speed data transfer client at: http://fasp.ncbi.nlm.nih.gov/1000genomes.html.
Users from the Europe and the rest of the would should download the mirrored 1000 Genomes data from the EBI at: ftp://ftp.1000genomes.ebi.ac.uk/. The EBI will be implementing an Aspera client in the near future.
The data available at the EBI and the NCBI are identical. Depending on server load and Internet connectivity some users in the Americas may have faster FTP downloads from the EBI and some users in Europe and the rest of the world may have faster downloads from NCBI.
Raw data for a portion of the project is already available through the Short Read Archive at the NCBI and the European Read Archive at the EBI. These comprehensive archives are specifically designed for short read data and will be making the complete project data available as soon as possible
The 1000 Genomes project plans to release summary data including positions of variants in individuals and populations. These data releases will include SNPs and CNV analysis for the six high-coverage individuals and all of the low coverage individuals. Quarterly data releases are planned starting in January 2009.